はじめに:過去記事を“AI編集者”に読ませたい
ブログを書き続けていると、
「自分の記事ってどんな傾向があるんだろう?」
「方向性を整理したいけど、読み返す時間がない…」
そんな瞬間、ありませんか?
私は今回、NotebookLM(GoogleのAIノート)を使って
過去記事をまとめて分析してもらうことにしました。
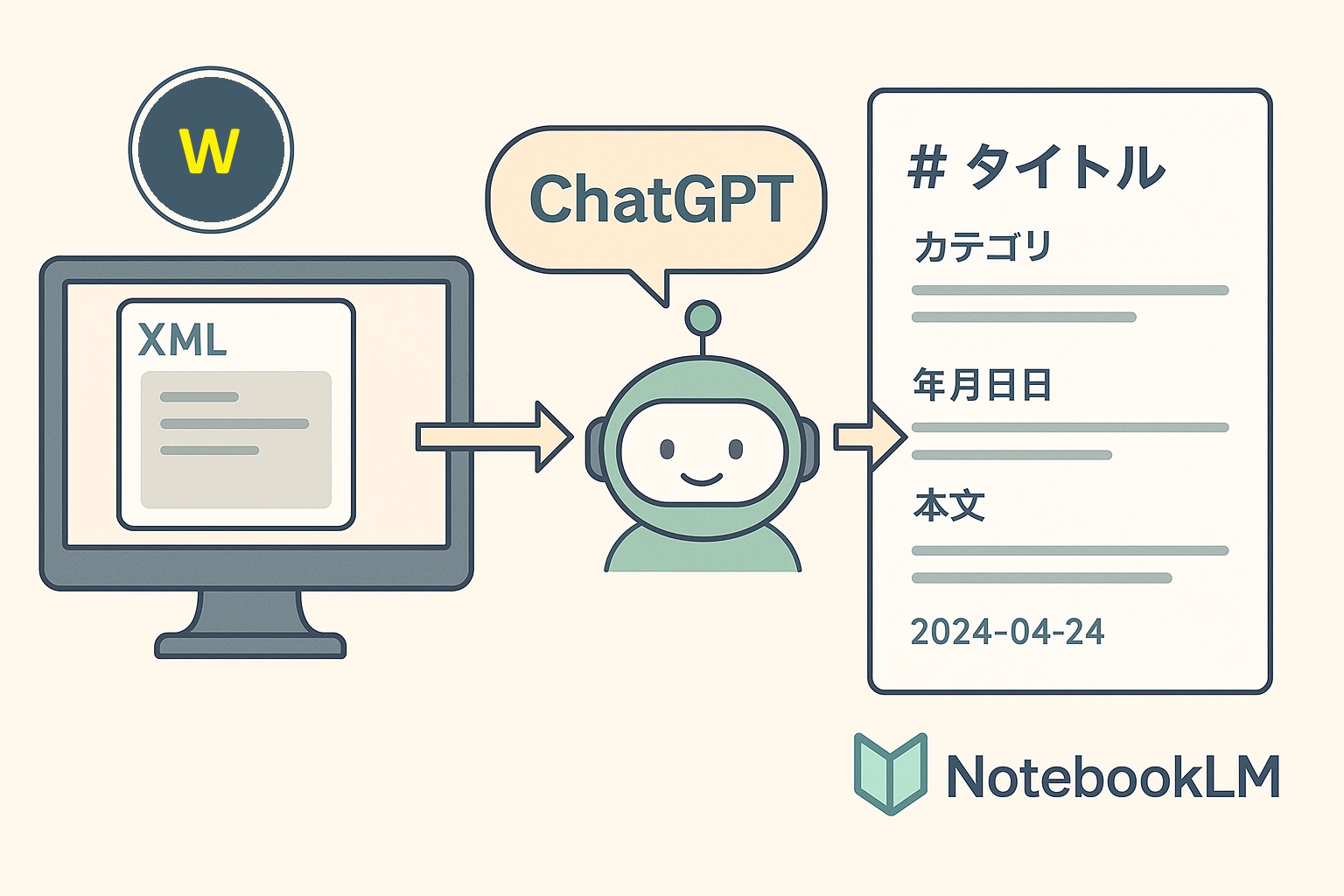
ただし、NotebookLMに直接WordPressの記事を読み込ませることはできません。
そこで、ChatGPTに頼んで「XML → TXT変換アプリ」を一緒に作ってみたんです。
WordPressから記事データをエクスポートする
まず、WordPressから記事データを取り出します。
標準機能でとても簡単です。
- 管理画面の「ツール」→「エクスポート」へ
- 「投稿」を選択
- 「エクスポートファイルをダウンロード」をクリック
これで .xml 形式のファイル(WXRファイル)が手に入ります。
この中に、タイトル・カテゴリ・本文・日付などがすべて含まれています。
ChatGPTと一緒に作った「変換アプリ」
次のステップは、このXMLをNotebookLMで読めるTXT形式に整えること。
ChatGPTに相談しながらPythonでGUIアプリを作りました。
🧩 使用技術:
- 言語:Python(標準ライブラリのみ)
- GUI:Tkinter
- 処理:XMLパース → テキスト整形
💻 開発のリアルタイム記録
開発にかかった時間は約20分。
途中、エラーが2回出ました。
❌ 本文が出力されない
→ 原因はcontent:encodedとexcerpt:encodedの混同。すぐ修正。❌ full_tag が未定義
→ 変数のスコープを見直して解決。
さらに、出力フォルダを自由に選べるようにフォルダ選択機能を1回追加。
結果、シンプルで使いやすいアプリに仕上がりました。
⚙️ 変換アプリの使い方
- アプリを起動
- 「XMLを選ぶ」ボタンでWordPressのエクスポートファイルを指定
- 出力先フォルダとファイル名を確認
- 「変換開始」をクリック
わずか数秒で、すべての記事がNotebookLM向けTXTファイルに変換されます。
100記事規模でも爆速。
出力形式はこんな感じ👇
# タイトル
大人になってからのギター入門|独学とレッスンの違い
# カテゴリ
ギター/音楽
# 投稿日
2024-12-18 10:00:00
# 本文
社会人になってからギターを始める人が増えています…
(本文続く)
---
HTMLタグやショートコードも削除されているので、NotebookLMでの読み込みがスムーズです。
実際のプログラムはこちら↓
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
NotebookLM Exporter (WXR → TXT)
--------------------------------
WordPressのエクスポートXML(WXR)をNotebookLM用TXTに変換するツール。
本文が出力されるよう修正済み。出力フォルダ選択機能を追加。
"""
import re
import sys
import traceback
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from html import unescape
from pathlib import Path
import xml.etree.ElementTree as ET
APP_TITLE = "NotebookLM Exporter (WXR → TXT)"
DEFAULT_OUT_NAME = "notebooklm_export.txt"
# --- HTMLクリーナ ---
SHORTCODE_PATTERN = re.compile(r"\[[^\[\]\n\r]*\]")
HTML_COMMENT_PATTERN = re.compile(r"<!--.*?-->", re.S)
SCRIPT_PATTERN = re.compile(r"<script.*?>.*?</script>", re.S | re.I)
STYLE_PATTERN = re.compile(r"<style.*?>.*?</style>", re.S | re.I)
TAG_PATTERN = re.compile(r"<[^>]+>")
MULTIBLANK_PATTERN = re.compile(r"\n{3,}")
TRAIL_SPACE_PATTERN = re.compile(r"[ \t]+\n")
def clean_html(html_text: str) -> str:
if not html_text:
return ""
text = unescape(html_text)
text = HTML_COMMENT_PATTERN.sub("", text)
text = SHORTCODE_PATTERN.sub("", text)
text = SCRIPT_PATTERN.sub("", text)
text = STYLE_PATTERN.sub("", text)
text = TAG_PATTERN.sub("", text)
text = text.replace("\xa0", " ").replace("\r\n", "\n").replace("\r", "\n")
text = TRAIL_SPACE_PATTERN.sub("\n", text)
text = MULTIBLANK_PATTERN.sub("\n\n", text)
return text.strip()
def convert_wxr_to_notebooklm_txt(xml_path: Path, out_path: Path):
ns = {
'content': 'http://purl.org/rss/1.0/modules/content/',
'wp': 'http://wordpress.org/export/1.2/'
}
context = ET.iterparse(str(xml_path), events=("start", "end"))
in_item = False
count = 0
out_path.parent.mkdir(parents=True, exist_ok=True)
with out_path.open('w', encoding='utf-8', newline='\n') as fout:
for event, elem in context:
tag_full = elem.tag
tag = tag_full.split('}', 1)[1] if '}' in tag_full else tag_full
if event == 'start' and tag == 'item':
in_item = True
data = {'title': '', 'date': '', 'type': '', 'status': '', 'categories': [], 'content_html': ''}
elif event == 'end' and in_item:
if tag == 'title':
data['title'] = (elem.text or '').strip()
elif tag == 'post_date':
data['date'] = (elem.text or '').strip()
elif tag == 'post_type':
data['type'] = (elem.text or '').strip()
elif tag == 'status':
data['status'] = (elem.text or '').strip()
elif tag == 'category' and elem.get('domain') == 'category':
if elem.text:
data['categories'].append(elem.text.strip())
elif tag == 'encoded':
if tag_full.startswith('{http://purl.org/rss/1.0/modules/content/}'):
data['content_html'] = elem.text or ''
elif tag == 'item':
in_item = False
if data['type'] == 'post' and data['status'] == 'publish':
content = clean_html(data['content_html'])
cats = '/'.join(data['categories'])
block = f"# タイトル\n{data['title']}\n\n# カテゴリ\n{cats}\n\n# 投稿日\n{data['date']}\n\n# 本文\n{content}\n\n---\n"
fout.write(block)
count += 1
elem.clear()
try:
root = context.root
if root is not None:
root.clear()
except Exception:
pass
return count
class App(ttk.Frame):
def __init__(self, master):
super().__init__(master)
self.master.title(APP_TITLE)
self.pack(fill=tk.BOTH, expand=True)
self.xml_path = tk.StringVar()
self.out_dir = tk.StringVar(value=str(Path.home()))
self.out_name = tk.StringVar(value=DEFAULT_OUT_NAME)
self._build_ui()
def _build_ui(self):
ttk.Label(self, text="WordPressエクスポートXML:").pack(anchor=tk.W, padx=8, pady=4)
ttk.Entry(self, textvariable=self.xml_path, width=80).pack(padx=8, pady=2)
ttk.Button(self, text="XMLを選ぶ", command=self.choose_xml).pack(padx=8, pady=4)
frm_out = ttk.LabelFrame(self, text="出力")
frm_out.pack(fill=tk.X, padx=8, pady=8)
row1 = ttk.Frame(frm_out)
row1.pack(fill=tk.X, pady=2)
ttk.Label(row1, text="出力フォルダ:").pack(side=tk.LEFT)
ttk.Entry(row1, textvariable=self.out_dir, width=60).pack(side=tk.LEFT, padx=8)
ttk.Button(row1, text="選択", command=self.choose_outdir).pack(side=tk.LEFT)
row2 = ttk.Frame(frm_out)
row2.pack(fill=tk.X, pady=2)
ttk.Label(row2, text="ファイル名:").pack(side=tk.LEFT)
ttk.Entry(row2, textvariable=self.out_name, width=40).pack(side=tk.LEFT, padx=8)
ttk.Button(self, text="変換開始", command=self.run_convert).pack(padx=8, pady=10)
self.txt_log = tk.Text(self, height=10)
self.txt_log.pack(fill=tk.BOTH, expand=True, padx=8, pady=8)
def log(self, msg):
self.txt_log.insert(tk.END, msg + "\n")
self.txt_log.see(tk.END)
def choose_xml(self):
path = filedialog.askopenfilename(filetypes=[("XMLファイル", "*.xml"), ("すべて", "*.*")])
if path:
self.xml_path.set(path)
base = Path(path).stem
self.out_name.set(f"{base}_notebooklm.txt")
def choose_outdir(self):
path = filedialog.askdirectory(title="出力先フォルダを選択")
if path:
self.out_dir.set(path)
def run_convert(self):
xml_path = Path(self.xml_path.get())
out_dir = Path(self.out_dir.get())
out_path = out_dir / self.out_name.get()
if not xml_path.exists():
messagebox.showerror(APP_TITLE, "XMLファイルを選択してください。")
return
try:
self.log("変換を開始します…")
count = convert_wxr_to_notebooklm_txt(xml_path, out_path)
self.log(f"完了: {count} 件を {out_path} に出力しました。")
messagebox.showinfo(APP_TITLE, f"完了しました! {count}件出力。")
except Exception as e:
self.log(traceback.format_exc())
messagebox.showerror(APP_TITLE, f"エラー: {e}")
def main():
root = tk.Tk()
App(root)
root.mainloop()
if __name__ == '__main__':
main()
NotebookLMでの活用方法
変換したTXTをNotebookLMにアップロードします。
- NotebookLMを開く
- 「新しいノートブックを作成」
- 「+ソースを追加」→ 変換したTXTファイルをアップロード
NotebookLMが自動で内容を解析してくれるので、
ブログ全体の傾向やテーマをAI視点で把握できます。
🧠 実際に使ったプロンプト例
- 「これらの記事の中で、最も多く扱っているテーマを教えてください」
- 「カテゴリごとの傾向をまとめてください」
- 「過去記事の内容から、新しく書けそうな記事案を提案してください」
NotebookLMが記事構造を理解しているので、
まるで自分専属の“AI編集者”がいるような感覚です。
まとめ:AIで記事整理がここまでラクになる
今回の流れをまとめると──
1️⃣ WordPressのエクスポート機能で .xml を取得
2️⃣ ChatGPTで作った変換アプリで .txt に変換
3️⃣ NotebookLMでAIに分析してもらう
これだけで、ブログ全体の方向性を可視化できました。
ChatGPTとNotebookLMの組み合わせは、まさにAI編集+AI分析の最強タッグです。
💬 最後にひとこと
ChatGPTと一緒に作業すると、思っている以上に“形になる”。
自分用ツールを作る体験は、ちょっとした発明のような楽しさがあります。